Chatbot Reliability: The Hidden Cost of AI Downtime
Chatbots are no longer "nice-to-have" features. They are revenue engines, cost reducers, and customer-facing digital employees operating 24/7.
When a chatbot goes down, the business doesn't just lose responses. It loses conversions, retention, trust and revenue.
The Most Dangerous Failures
They're silent failures. No error banners. No outage notifications. No visible warnings. Just slower responses and delayed interactions. By the time the business notices, the damage is already done.
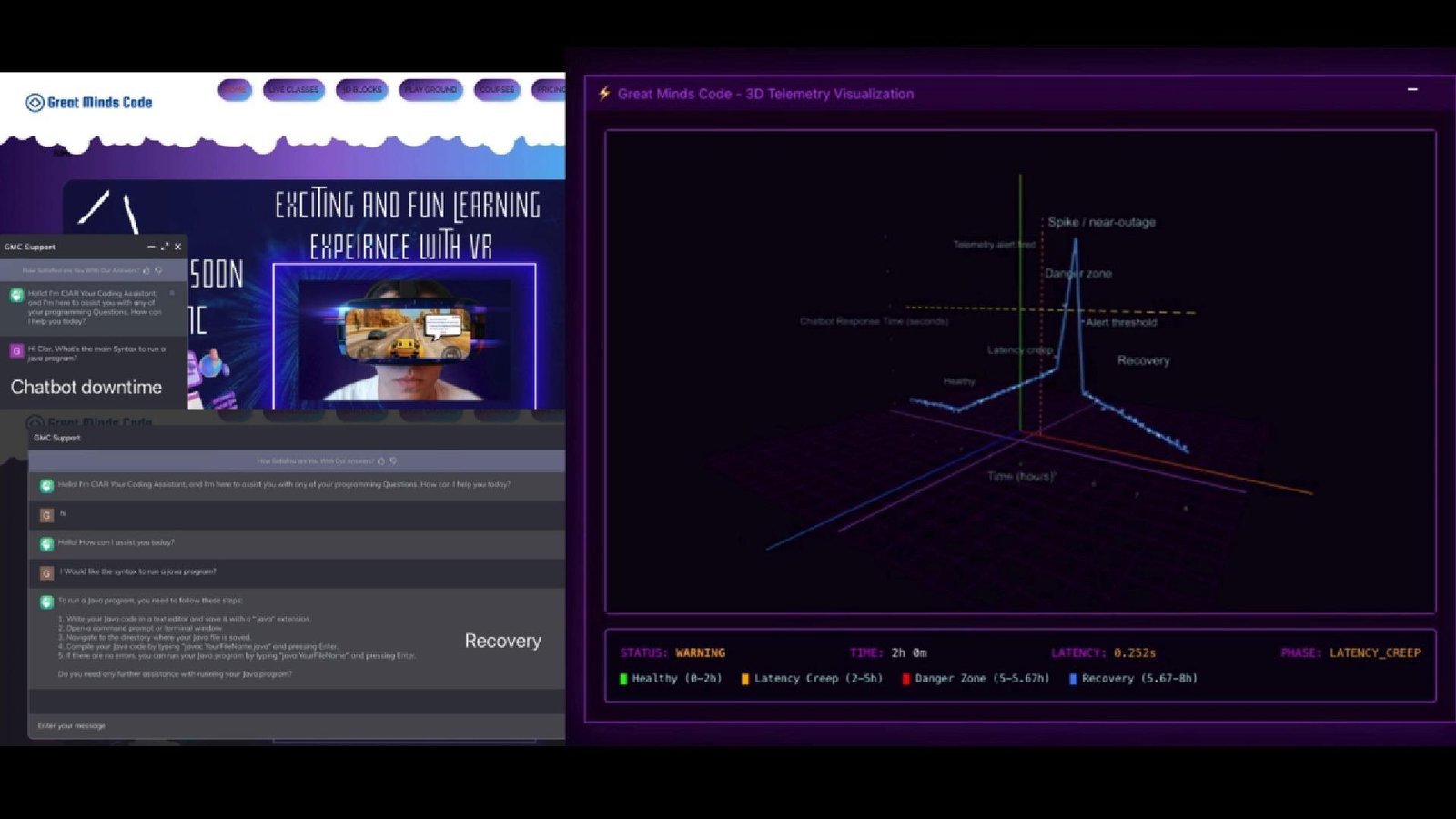
The Great Minds Code Incident
We saw this firsthand in production with Great Minds Code. The chatbot looked healthy:
But underneath, the system had stalled:
One of the Most Costly AI Failure Modes
The UI is alive, but the intelligence layer is unavailable. To users, it feels like: "Why is it slow?" "Why isn't it responding?"
To the business, it means:
Why Telemetry Matters
Telemetry turns chatbots from opaque, non-observable systems into fully instrumented production services detecting performance drift, upstream instability, and failure thresholds before users notice and revenue is impacted.
Reliable AI isn't only about Large Language Model capability and inference quality, it's about end-to-end observability, operational assurance, and service reliability.
What Really Causes Chatbot Downtime (In Business Terms)
Chatbot downtime is rarely a single "failure." It's usually a breakdown in dependencies, visibility, or control. Here are the most common causes — reframed in business language.
1 Dependency Failures
Revenue Coupled to External Services
Modern chatbots rely on third-party services: LLM providers, vector databases, tool APIs.
What Goes Wrong
- API credentials expire
- Billing interruptions occur
- Usage limits are exceeded
| Without Telemetry | With Telemetry |
|---|---|
| The system appears idle | Immediate visibility into authentication failures, quota exhaustion |
2 Infrastructure Saturation
Your Digital Employee Shows Up But Can't Work
If your chatbot backend runs on cloud or containerized infrastructure: servers can crash, resources can max out, auto-sleep or restarts can occur.
| Without Telemetry | With Telemetry |
|---|---|
| The system looks online but fails silently | Real-time visibility into missing heartbeats, timeout spikes |
3 Configuration Drift
The System Is Running, But Misconfigured
Restarts, deployments, or environment changes can silently remove: API keys, model configurations, database connections.
Business Impact
The chatbot is technically "up," but functionally useless.
| Without Observability | With Observability |
|---|---|
| Failure mode is invisible until users complain | Misconfiguration errors surface immediately with clear root cause |
4 Client-to-Server Breakdowns
Messages Sent, Nothing Received
Security and delivery issues such as: HTTPS/HTTP mismatches, CORS restrictions, domain or DNS misalignment.
| Without Telemetry | With Telemetry |
|---|---|
| Assume backend failure when issue is delivery | Instantly see client-side request blocking and fix it |
5 Upstream Provider Instability
Your House Is Fine, But the Street Is Flooded
Even when your system is healthy: LLM providers, vector databases, external tools can experience outages or degradation.
| Without Telemetry | With Telemetry |
|---|---|
| Speculate about cause while revenue leaks | See exactly where value chain broke and trigger fallbacks |
The Core Business Problem: Lack of Visibility
The Real Issue in the Great Minds Code Incident
The biggest issue wasn't what failed. It was this: Nothing told the business that something was failing.
The chatbot didn't crash. It degraded. And silent degradation is the most expensive failure mode because:
What Telemetry Changes for the Business
With proper telemetry in place, Great Minds Code would have seen:
Response Latency
Creeping beyond acceptable thresholds
Error Rates
Rising before total failure
Heartbeat Signals
Disappearing from upstream services
Dependency Failures
Detected before cascading effects
Before students noticed. Before learning was disrupted. Before trust was lost.
Reacting vs. Preventing
That's the difference between reacting to complaints and preventing revenue loss.
Telemetry transforms a chatbot from a black box into a managed business system. It answers critical questions before customers ask them:
Performance
Is performance degrading?
Dependencies
Which dependency is becoming risky?
Costs
Are retries inflating costs?
Latency
Is latency creeping up quietly?
Thresholds
Are we approaching a failure threshold?
Telemetry Turns AI From a Cost Center Into a Controlled Asset
Metrics give leadership the pulse • Logs provide operational memory • Traces expose the full value chain
The Final Word
Together, telemetry gives the business control over what was once an unpredictable black box. When chatbots are reliable, they truly become revenue engines, cost reducers, and effective 24/7 digital employees.
Invest in observability before you invest in more AI features. The silent failures are costing you more than you know.
Key Takeaway
Silent chatbot degradation is the most expensive failure mode. Telemetry transforms AI systems from unpredictable cost centers into controlled, observable business assets that deliver reliable ROI.
**prodentim**
ProDentim is a distinctive oral-care formula that pairs targeted probiotics with plant-based ingredients to encourage strong teeth, comfortable gums, and reliably fresh breath
**herpafend official**
Herpafend is a natural wellness formula developed for individuals experiencing symptoms related to the herpes simplex virus. It is designed to help reduce the intensity and frequency of flare-ups while supporting the bodys immune defenses.
**prostafense official**
ProstAfense is a premium, doctor-crafted supplement formulated to maintain optimal prostate function, enhance urinary performance, and support overall male wellness.
**mounja boost**
MounjaBoost is a next-generation, plant-based supplement created to support metabolic activity, encourage natural fat utilization, and elevate daily energywithout extreme dieting or exhausting workout routines.
**neuro sharp**
Neuro Sharp is an advanced cognitive support formula designed to help you stay mentally sharp, focused, and confident throughout your day.
**men balance**
MEN Balance Pro is a high-quality dietary supplement developed with research-informed support to help men maintain healthy prostate function.
**aquasculpt**
aquasculpt is a premium metabolism-support supplement thoughtfully developed to help promote efficient fat utilization and steadier daily energy.
**boostaro reviews**
Boostaro is a purpose-built wellness formula created for men who want to strengthen vitality, confidence, and everyday performance.
**backbiome**
Mitolyn is a carefully developed, plant-based formula created to help support metabolic efficiency and encourage healthy, lasting weight management.
Romance takes a slightly different turn in this book, focusing more on slow-burn tension and deep emotional connections rather than instant infatuation. The relationship dynamics are mature and complicated, reflecting the war-torn world the characters inhabit. Whether you have the hardcover or a Queen of Shadows pdf, the chemistry between the characters is palpable. Rowan’s loyalty and Aelin’s fierce independence create a partnership that fans adore. It is a refreshing take on the romantic subplots typical of the genre, prioritizing trust and shared goals over simple attraction. https://queenofshadowspdf.site/ Dnd 5E Dragonlance Shadow Of The Dragon Queen Pdf
Thank you for putting this in a way that anyone can understand.
I’ll definitely come back and read more of your content.
Thanks for the auspicious writeup. It in fact was a amusement account it. Glance advanced to more brought agreeable from you! By the way, how could we be in contact?
Rajaluckgamedownload! Downloading now…hope it’s as lucky as the name suggests! Wish me luck. You should try: rajaluckgamedownload
Finally found a working khelo 24 bet apk download! The download was easy peasy and the app installed without a hitch. It’s legit! Find the link here khelo 24 bet apk download
Anyone seen the Sky Lucky Jackpot results for today? Gotta go check if I’m a winner! Find the results here: sky lucky jackpot results today
**finessa**
Finessa is a natural supplement made to support healthy digestion, improve metabolism, and help you achieve a flatter belly.
That’s a great point about balancing accessibility with depth in game design! Seeing platforms like jboss casino prioritize easy registration & localized payments (like GCash) is smart for the PH market. Really boosts player experience!
**backbiome**
Backbiome is a naturally crafted, research-backed daily supplement formulated to gently relieve back tension and soothe sciatic discomfort.
Slot tại xn88 có theme đa dạng: Ai Cập, thần thoại, phương Tây, châu Á… thỏa mãn mọi sở thích. TONY03-07O
Been using Wazambalogin for a few weeks. Login is easy and I like that they are mobile optimized. Check them out wazambalogin.
Casinochillbet is a smooth all-around option. They are very player friendly. I would recommend checking them out via casinochillbet.
88ppbet? Heard some buzz about this one. Might give it a shot this weekend and see if it lives up to the hype. Fingers crossed! Check it out here: 88ppbet
**boostaro**
Boostaro is a purpose-built wellness formula created for men who want to strengthen vitality, confidence, and everyday performance.
**prostafense**
ProstAfense is a premium, doctor-crafted supplement formulated to maintain optimal prostate function, enhance urinary performance, and support overall male wellness.
New Braunfels Garage Door Repair offers same-day Garage Door Emergencies service and 24/7 assistance. They use high-quality materials from trusted brands like Amarr, Clopay, and Wayne-Dalton to ensure durable and reliable solutions. Whether you’re looking to install a new garage door, replace an existing one, or need prompt repairs, their team is ready to assist you.
Just retired to tech hobbies! Table Games Casino offers classic blackjack and roulette with secure live dealers. Try their seamless app access via table games casino link today for authentic fun at home.
Interesting read! The focus on localized payment options, like GCash, is smart for the Philippine market. Secure platforms are key – check out jl111 app download for a regulated experience. Account verification is a must for trust, too!